那些用Go实现的分布式事务框架(2)
开篇
上一篇我们主要介绍的是seata-golang。一个对标seata的go语言实现,当然版本还是落后Java版很多的。
这次我们来介绍一下另一个go实现的分布式事务:dtm。
首先来看下dtm整体架构图(来源官网)。
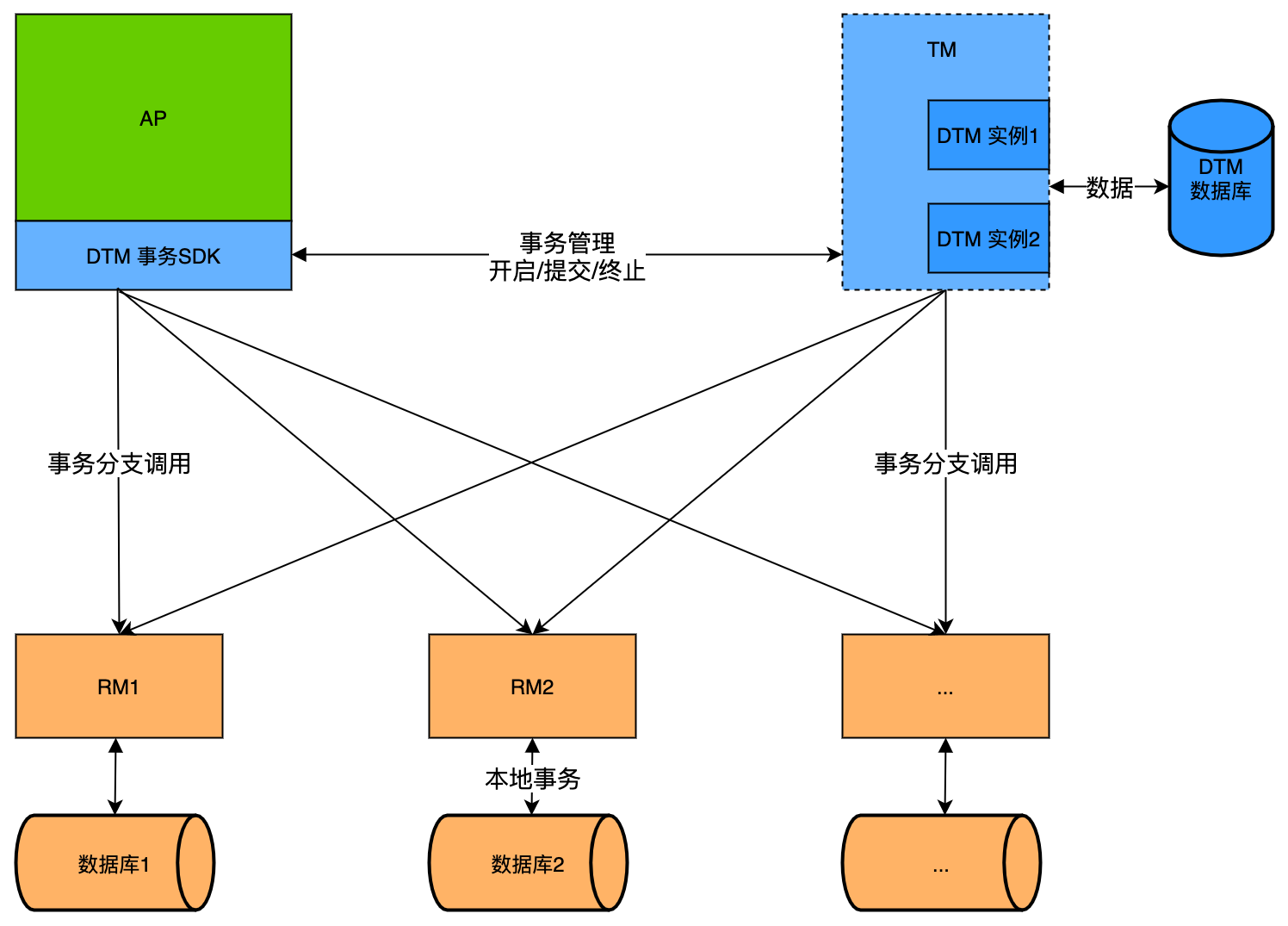
再来看之前的seata架构图。
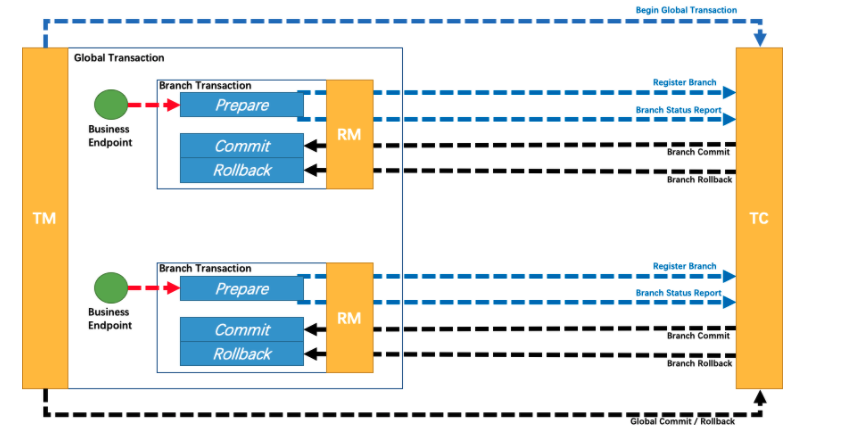
从架构上来看,大差不差。
seata中的TC对标dam的TM。
RM两边意思一致。
seata中的TM对标dtm事务SDK。作用都是一样:第一阶段开启一个全局事务,执行各RM分支事务,第二阶段根据RM第一阶段执行结果,决定调用TC(seata)|TM(dtm) commit或者rollback。
架构上,个人感觉只是因为模块名称以及图画不一样的差别。
当然在实现细节上还是有很大差别的。
我们先简单介绍下DTM各个模块。
TM
TM 层在代码中是没有具体的主体结构的,开始都是函数之前的调用。
启动TM实际上开启了两个服务,http以及grpc这两个服务。
// StartSvr StartSvr
func StartSvr() {
app := common.GetGinApp()
app = httpMetrics(app)
addRoute(app)
dtmimp.Logf("dtmsvr listen at: %d", common.DtmHttpPort)
go app.Run(fmt.Sprintf(":%d", common.DtmHttpPort))
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", common.DtmGrpcPort))
dtmimp.FatalIfError(err)
s := grpc.NewServer(
grpc.UnaryInterceptor(grpc_middleware.ChainUnaryServer(
grpc.UnaryServerInterceptor(grpcMetrics), grpc.UnaryServerInterceptor(dtmgimp.GrpcServerLog)),
))
dtmgimp.RegisterDtmServer(s, &dtmServer{})
dtmimp.Logf("grpc listening at %v", lis.Addr())
go func() {
err := s.Serve(lis)
dtmimp.FatalIfError(err)
}()
go updateBranchAsync()
// 省略代码
}
http路由,
func addRoute(engine *gin.Engine) {
engine.GET("/api/dtmsvr/newGid", common.WrapHandler(newGid)) //开启一个分布式事务,得到分布式事务唯一id
engine.POST("/api/dtmsvr/prepare", common.WrapHandler(prepare))
engine.POST("/api/dtmsvr/submit", common.WrapHandler(submit))
engine.POST("/api/dtmsvr/abort", common.WrapHandler(abort))
//......
}
gRPC接口,
// dtmServer is used to implement dtmgimp.DtmServer.
type dtmServer struct {
pb.UnimplementedDtmServer
}
func (s *dtmServer) NewGid(ctx context.Context, in *emptypb.Empty) (*dtmgimp.DtmGidReply, error) {
return &dtmgimp.DtmGidReply{Gid: GenGid()}, nil
}
func (s *dtmServer) Submit(ctx context.Context, in *pb.DtmRequest) (*emptypb.Empty, error) {
r, err := svcSubmit(TransFromDtmRequest(in))
return &emptypb.Empty{}, dtmgimp.Result2Error(r, err)
}
func (s *dtmServer) Prepare(ctx context.Context, in *pb.DtmRequest) (*emptypb.Empty, error) {
r, err := svcPrepare(TransFromDtmRequest(in))
return &emptypb.Empty{}, dtmgimp.Result2Error(r, err)
}
func (s *dtmServer) Abort(ctx context.Context, in *pb.DtmRequest) (*emptypb.Empty, error) {
r, err := svcAbort(TransFromDtmRequest(in))
return &emptypb.Empty{}, dtmgimp.Result2Error(r, err)
}
即然提供了两个服务入口,那理所当然有公共处理核心业务的部分。
// 提交事务请求操作
func svcSubmit(t *TransGlobal) (interface{}, error) {
db := dbGet()
t.Status = dtmcli.StatusSubmitted
err := t.saveNew(db)
if err == errUniqueConflict {
dbt := transFromDb(db.DB, t.Gid, false)
if dbt.Status == dtmcli.StatusPrepared {
updates := t.setNextCron(cronReset)
dbr := db.Must().Model(&TransGlobal{}).Where("gid=? and status=?", t.Gid, dtmcli.StatusPrepared).Select(append(updates, "status")).Updates(t)
checkAffected(dbr)
} else if dbt.Status != dtmcli.StatusSubmitted {
return map[string]interface{}{"dtm_result": dtmcli.ResultFailure, "message": fmt.Sprintf("current status '%s', cannot sumbmit", dbt.Status)}, nil
}
}
return t.Process(db), nil
}
// 准备事务请求
func svcPrepare(t *TransGlobal) (interface{}, error) {
t.Status = dtmcli.StatusPrepared
err := t.saveNew(dbGet())
////.........
}
// 中断事务
func svcAbort(t *TransGlobal) (interface{}, error) {
db := dbGet()
dbt := transFromDb(db.DB, t.Gid, false)
// ......
}
// 注册分支
func svcRegisterBranch(branch *TransBranch, data map[string]string) (ret interface{}, rerr error) {
err := dbGet().Transaction(func(db *gorm.DB) error {
dbt := transFromDb(db, branch.Gid, true)
///.......
}
TM对数据的存储管理并不是依赖于接口,而是依赖于common.DB 结构。根据配置文件中DB.driver 的值决定底层数据库是mysql还是postgres两种。
func dbGet() *common.DB {
return common.DbGet(config.DB)
}
// DbGet get db connection for specified conf
func DbGet(conf map[string]string) *DB {
dsn := dtmimp.GetDsn(conf)
//.....
}
// GetDsn get dsn from map config
func GetDsn(conf map[string]string) string {
host := MayReplaceLocalhost(conf["host"])
driver := conf["driver"]
dsn := map[string]string{
"mysql": fmt.Sprintf("%s:%s@tcp(%s:%s)/%s?charset=utf8mb4&parseTime=true&loc=Local",
conf["user"], conf["password"], host, conf["port"], conf["database"]),
"postgres": fmt.Sprintf("host=%s user=%s password=%s dbname='%s' port=%s sslmode=disable",
host, conf["user"], conf["password"], conf["database"], conf["port"]),
}[driver]
PanicIf(dsn == "", fmt.Errorf("unknow driver: %s", driver))
return dsn
}
再看这个DB结构,所以本质上无论底层是哪种数据库,都是直接依赖gorm来对数据进行操作的。
// DB provide more func over gorm.DB
type DB struct {
*gorm.DB
}
接着,看下TM是如何通知各个RM进行commit或者rollback的?
举一个TCC模式的例子。
TCC的两个阶段。
- 阶段一: try。尝试执行,调用各RM自定义的try行为,预留必要的业务资源。
- 阶段二:Confirm(阶段一所有参与本次事务的try行为都成功)。调用各分支事务的Confirm方法,真正执行业务,并且只使用try阶段预留的资源。
- 阶段二:Cancel(阶段一任一参与本次事务的try行为失败)。调用各分支事务的Cancel方法,释放一阶段try所预留的资源。
从上面我们可以得知,TCC模式下,TM在第二阶段要么通知各分支事务Confirm要么Cancel。
在注册各RM事务分支到TM的时候,最终TM会为每一个分布式事务的参与者(RM)生成两条分支信息。
就像这样,
gid(分布式事务id) url(rm请求地址) data(数据) op(操作类型比如:confirm|cancel)
520xxx xxx.com/confirm xxx. confirm
520xxx xxx.com/cancel xxx cancel
对,就是把对应的RM资源操作地址直接存入。
当TM接收到commit或者rollback命令,在处理完自身逻辑(一般就是修改Gloable状态),就需要开始处理每一个注册进来的分支事务了,说白了就是需要调用各个分支事务对应操作的接口。
func (t *TransGlobal) processInner(db *common.DB) (rerr error) {
//....
branches := []TransBranch{}
db.Must().Where("gid=?", t.Gid).Order("id asc").Find(&branches)
t.lastTouched = time.Now()
rerr = t.getProcessor().ProcessOnce(db, branches)
return
}
这里的t.getProcessor() 是需要根据当前事务的类型(TCC、SAGA、XA)获取到对应的处理器来进行逻辑的处理。
func (t *TransGlobal) getProcessor() transProcessor {
return processorFac[t.TransType](t)
}
当然,每个事务处理器只需要实现接口,
type transProcessor interface {
GenBranches() []TransBranch
ProcessOnce(db *common.DB, branches []TransBranch) error
}
真正调用RM资源服务地址的时候,分为http和grpc,这是由开发者决定的。
func (t *TransGlobal) getURLResult(url string, branchID, op string, branchPayload []byte) (string, error) {
if t.Protocol == "grpc" {
dtmimp.PanicIf(strings.HasPrefix(url, "http"), fmt.Errorf("bad url for grpc: %s", url))
server, method, err := dtmdriver.GetDriver().ParseServerMethod(url)
if err != nil {
return "", err
}
conn := dtmgimp.MustGetGrpcConn(server, true)
ctx := dtmgimp.TransInfo2Ctx(t.Gid, t.TransType, branchID, op, "")
err = conn.Invoke(ctx, method, branchPayload, []byte{})
//....
}
dtmimp.PanicIf(!strings.HasPrefix(url, "http"), fmt.Errorf("bad url for http: %s", url))
resp, err := dtmimp.RestyClient.R().SetBody(string(branchPayload)).
SetQueryParams(map[string]string{
"gid": t.Gid,
"trans_type": t.TransType,
"branch_id": branchID,
"op": op,
}).
SetHeader("Content-type", "application/json").
Execute(dtmimp.If(branchPayload != nil || t.TransType == "xa", "POST", "GET").(string), url)
if err != nil {
return "", err
}
return resp.String(), nil
}
在v1.6之前的版本,grpc的请求是很简单粗暴解析地址方法然后连接的。
//v1.6之前
func (t *TransGlobal) getURLResult(url string, branchID, op string, branchPayload []byte) (string, error) {
if t.Protocol == "grpc" {
dtmimp.PanicIf(strings.HasPrefix(url, "http"), fmt.Errorf("bad url for grpc: %s", url))
server, method := dtmgimp.GetServerAndMethod(url)
conn := dtmgimp.MustGetGrpcConn(server, true)
ctx := dtmgimp.TransInfo2Ctx(t.Gid, t.TransType, branchID, op, "")
err := conn.Invoke(ctx, method, branchPayload, []byte{})
if err == nil {
return dtmcli.ResultSuccess, nil
}
//......
}
}
func GetServerAndMethod(grpcURL string) (string, string) {
fs := strings.Split(grpcURL, "/")
server := fs[0]
method := "/" + strings.Join(fs[1:], "/")
return server, method
}
现在为了支持那些采用gRPC Resolver 机制之上的一些微服务框架接入,做了一块抽象。感兴趣可以看下,这里就不介绍了。
SDK
至于SDK,每一个事务模式都是独立的,本质上是没有关联的。比如下面我们启动一个TCC分布式事务。这个分布式事务是由两个服务组成,简称+30和-30的服务。
gid := dtmcli.MustGenGid(DtmHttpServer)
err := dtmcli.TccGlobalTransaction(DtmHttpServer, gid, func(tcc *dtmcli.Tcc) (*resty.Response, error) {
resp, err := tcc.CallBranch(&TransReq{Amount: 30}, Busi+"/TransOut", Busi+"/TransOutConfirm", Busi+"/TransOutRevert")
if err != nil {
return resp, err
}
return tcc.CallBranch(&TransReq{Amount: 30}, Busi+"/TransIn", Busi+"/TransInConfirm", Busi+"/TransInRevert")
})
// dtm dtm服务器地址
// gid 全局事务id
// tccFunc tcc事务函数,里面会定义全局事务的分支
func TccGlobalTransaction(dtm string, gid string, tccFunc TccGlobalFunc) (rerr error) {
tcc := &Tcc{TransBase: *dtmimp.NewTransBase(gid, "tcc", dtm, "")}
rerr = dtmimp.TransCallDtm(&tcc.TransBase, tcc, "prepare")
if rerr != nil {
return rerr
}
// 小概率情况下,prepare成功了,但是由于网络状况导致上面Failure,那么不执行下面defer的内容,等待超时后再回滚标记事务失败,也没有问题
defer func() {
x := recover()
operation := dtmimp.If(x == nil && rerr == nil, "submit", "abort").(string)
err := dtmimp.TransCallDtm(&tcc.TransBase, tcc, operation)
if rerr == nil {
rerr = err
}
if x != nil {
panic(x)
}
}()
_, rerr = tccFunc(tcc)
return
}
// CallBranch call a tcc branch
func (t *Tcc) CallBranch(body interface{}, tryURL string, confirmURL string, cancelURL string) (*resty.Response, error) {
branchID := t.NewSubBranchID()
err := dtmimp.TransRegisterBranch(&t.TransBase, map[string]string{
"data": dtmimp.MustMarshalString(body),
"branch_id": branchID,
BranchConfirm: confirmURL,
BranchCancel: cancelURL,
}, "registerTccBranch")
if err != nil {
return nil, err
}
return dtmimp.TransRequestBranch(&t.TransBase, body, branchID, BranchTry, tryURL)
}
从上面的调用中我们还是能还原出整体流程。
- 调用TM,得到一个分布式id
- 调用TccGlobalTransaction函数开启分布式事务。
- 调用TM prepare(这步只是为了查看第一步产生的那个分布式事务状态是否处于prepare。这里没看明白,此时还未注册执行分支,全局状态不是应该只会存在初始化状态吗)
- 上一步没问题,执行传入的闭包函数,即CallBranch 函数里向TM注册参与事务的TM分支。注册完成后,开始第一阶段调用各分支的try服务。
- 各分支try服务调用结束,根据第一阶段结果决定通知TM是submit还是abort。
代码还是很好懂的。
另外提一点,分布式事务常见的一些问题:比如空补偿、重挂等问题。
一般情况下,业务需要自行去处理这种场景,以免造成不可描述的错误。
dtm里面提供了对应子事务屏障方案。核心就在,
originAffected, _ := insertBarrier(tx, ti.TransType, ti.Gid, ti.BranchID, originType, bid, ti.Op)
currentAffected, rerr := insertBarrier(tx, ti.TransType, ti.Gid, ti.BranchID, ti.Op, bid, ti.Op)
dtmimp.Logf("originAffected: %d currentAffected: %d", originAffected, currentAffected)
if (ti.Op == BranchCancel || ti.Op == BranchCompensate) && originAffected > 0 || // 这个是空补偿
currentAffected == 0 { // 这个是重复请求或者悬挂
return
}
rerr = busiCall(tx)
其实就是利用数据库的唯一索引机制,当然每个RM资源你都得新增一张表。
上面提到,dtm的TM角色本质上就是对应 seata 中的 TC,但是他们的处理模式是不同的。
dtm中的TM会根据注册时的各分支保存的地址,决定通过http还是rpc调用各RM操作,是由TM直接发起对RM的请求。
seata-go的实现中,TC是不参与直接调用RM的。
还记得上篇提到一个双向流RPC接口(BranchCommunicate)。TC通过这个接口把对应分支处理信息传递给RM管理器。
// ........
switch msg.BranchMessageType {
// 分支commit消息
case apis.TypeBranchCommit:
request := &apis.BranchCommitRequest{}
data := msg.GetMessage().GetValue()
err := request.Unmarshal(data)
if err != nil {
log.Error(err)
continue
}
response, err := manager.BranchCommit(context.Background(), request)
if err == nil {
content, err := types.MarshalAny(response)
if err == nil {
manager.branchMessages <- &apis.BranchMessage{
ID: msg.ID,
BranchMessageType: apis.TypeBranchCommitResult,
Message: content,
}
}
}
// 分支rollback消息
case apis.TypeBranchRollback:
//........
}
}
//....
然后由RM管理器根据事务类型选择对应的事务管理器进行处理,最终调用的是对应事务类型管理器的BranchCommit方法。
// 分支commit
func (manager ResourceManager) BranchCommit(ctx context.Context, request *apis.BranchCommitRequest) (*apis.BranchCommitResponse, error) {
rm, ok := manager.managers[request.BranchType]
if ok {
return rm.BranchCommit(ctx, request)
}
return &apis.BranchCommitResponse{
ResultCode: apis.ResultCodeFailed,
Message: fmt.Sprintf("there is no resource manager for %s", request.BranchType.String()),
}, nil
}
下面是一个TCC事务类型管理器的处理。
// 只留核心代码
func (resourceManager TCCResourceManager) BranchCommit(ctx context.Context, request *apis.BranchCommitRequest) (*apis.BranchCommitResponse, error) {
resource := resourceManager.ResourceCache[request.ResourceID]
if resource == nil {
// ....
}
tccResource := resource.(*TCCResource)
if tccResource.CommitMethod == nil {
// .....
}
result := false
businessActionContext := getBusinessActionContext(request.XID, request.BranchID, request.ResourceID, request.ApplicationData)
args := make([]interface{}, 0)
args = append(args, businessActionContext)
// 最终执行
returnValues := proxy.Invoke(tccResource.CommitMethod, nil, args)
// ...
}
对应的事务RM管理器是如何通知、处理各个RM资源的。原理就是我上篇提到的作者实现的一个全局事务代理模式,本质上是利用go的反射实现的,感兴趣的可以自己去扒下源码,也可以看看作者对实现全局事务代理的介绍。
总结
这篇文章主要介绍了dtm实现的一些细节,从这两篇文章大体能看出实现上的部分区别,更多的细节还得靠自己去挖掘。
最后再问几个问题,
- 日常开发中你们哪些场景是用到了分布式事务?用的是哪个框架还是自研的?
- 或者说在分布式环境下,一致性的问题你们是如何解决的?
相关文章
