Go netpoll大解析
开篇
之前简单看过一点go原生netpoll,没注意太多细节。最近从头到尾看了一遍,特写篇文章记录下。文章很长,请耐心看完,一定有所收获。
用户空间和内核空间
在linux中,经常能看到两个词语:User space(用户空间)和Kernel space (内核空间)。
简单的说, Kernel space是linux内核运行的空间,User space是用户程序运行的空间。它们之间是相互隔离的。
现代操作系统都是采用虚拟存储器。那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核,保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。空间分配如下图所示:
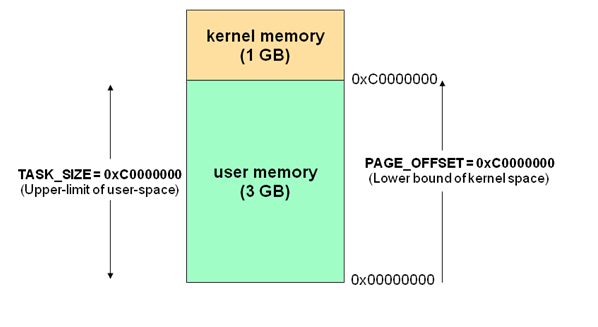
Kernel space可以调用系统的一切资源。User space 不能直接调用系统资源,在 Linux系统中,所有的系统资源管理都是在内核空间中完成的。比如读写磁盘文件、分配回收内存、从网络接口读写数据等等。应用程序无法直接进行这样的操作,但是用户程序可以通过内核提供的接口来完成这样的任务。
比如像下面这样,

应用程序要读取磁盘上的一个文件,它可以向内核发起一个 “系统调用” 告诉内核:”我要读取磁盘上的某某文件”。其实就是通过一个特殊的指令让进程从用户态进入到内核态,在内核空间中,CPU 可以执行任何的指令,当然也包括从磁盘上读取数据。具体过程是先把数据读取到内核空间中,然后再把数据拷贝到用户空间并从内核态切换到用户态。此时应用程序已经从系统调用中返回并且拿到了想要的数据,继续往下执行用户空间执行逻辑。
这样的话,一旦涉及到对I/O的处理,就必然会涉及到在用户态和内核态之间来回切换。
io模型
网上有太多关于I/O模型的文章,看着看着有可能就跑偏了,所以我还是从 «UNIX 网络编程» 中总结的5中I/O模型说起吧。
Unix可用的5种I/O模型。
- 阻塞I/O
- 非阻塞I/O
- I/O复用
- 信号驱动式I/O(SIGIO)
- 异步I/O(POSIX的aio_系列函数)
阻塞I/O
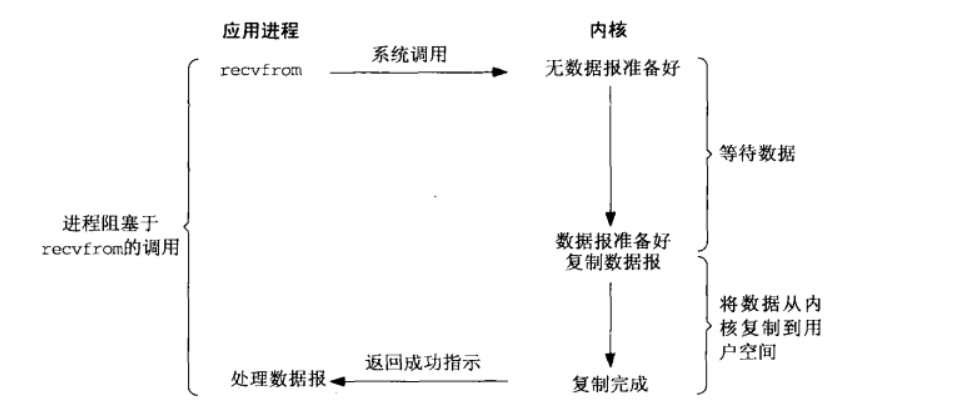
阻塞式I/O下,进程调用recvfrom,直到数据到达且被复制到应用程序的缓冲区中或者发生错误才返回,在整个过程进程都是被阻塞的。
非阻塞I/O
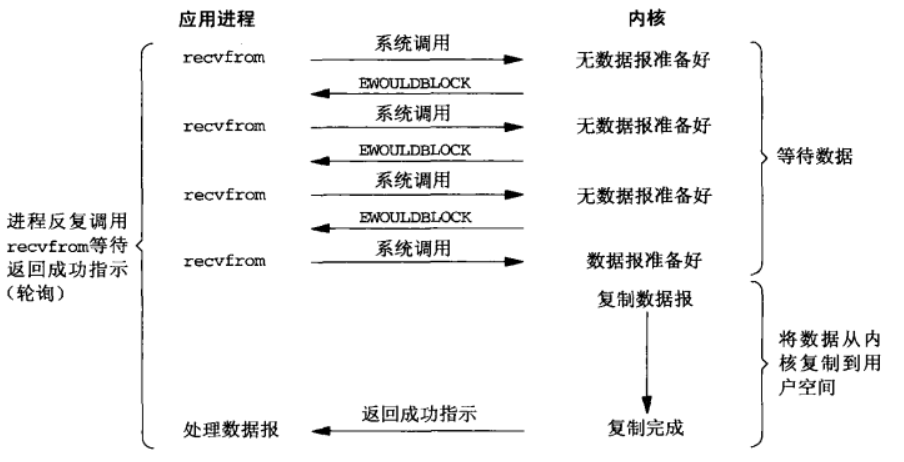
从图中可以看出,前三次调用recvfrom中没有数据可返回,因此内核转而立即返回一个EWOULDBLOCK错误。第四次调用recvfrom时已有一个数据报准备好,它被复制到应用程序缓冲区,于是recvfrom成功返回。
当一个应用程序像这样对一个非阻塞描述符循环调用recvfrom时,我们通常称为轮询(polling),持续轮询内核,以这种方式查看某个操作是否就绪。
I/O多路复用
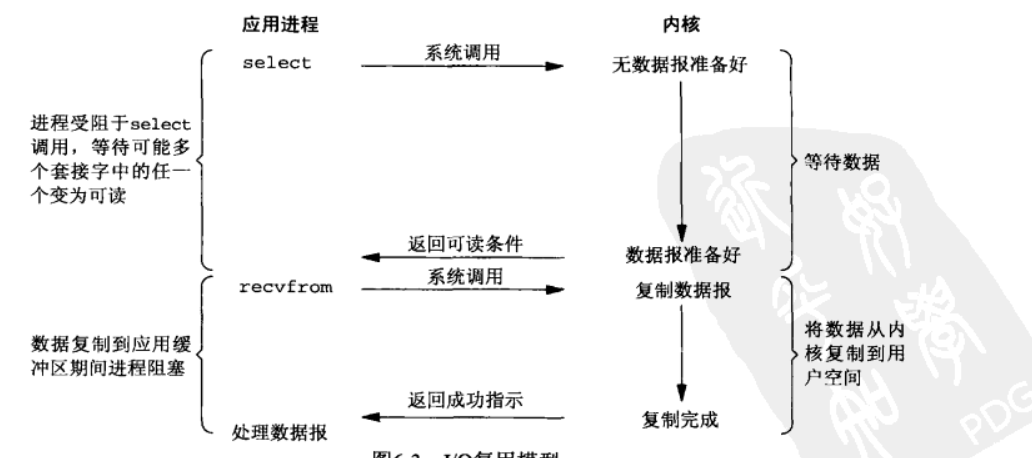
有了I/O多路复用(I/O multiplexing),我们就可以调用 select 或者 poll,阻塞在这两个系统调用中的某一个之上,而不是阻塞在真正的I/O系统调用上。
上面这句话难理解是吧,说白了这里指的是,在第一步中,我们只是阻塞在select调用上,直到数据报套接字变为可读,返回可读条件,这里并没有发生I/O事件,所以说这一步,并没有阻塞在真正的I/O系统调用上。
其他两种就不过多介绍了。
还有一点,我们会经常提到同步I/O和异步I/O。
POSIX 把这两种术语定义如下:
- 同步I/O操作(synchronous I/O opetation) 导致请求进程被阻塞,直到I/O操作完成。
- 异步I/O(asynchronous opetation) 不导致请求进程被阻塞。
基于上面的定义,

异步I/O的关键在于第二步的recrfrom是否会阻塞住用户进程,如果不阻塞,那它就是异步I/O。从上面汇总图中可以看出,只有异步I/O满足POSIX中对异步I/O的定义。
Go netpoller
Go netpoller 底层就是对I/O多路复用的封装。不同平台对I/O多路复用有不同的实现方式。比如Linux的select、poll和epoll(具体差别不是很明白可以看这篇)。在MacOS则是kqueue,而Windows是基于异步I/O实现的icop……,基于这些背景,Go针对不同的平台调用实现了多版本的netpoller。
下面我们通过一个demo开始讲解。
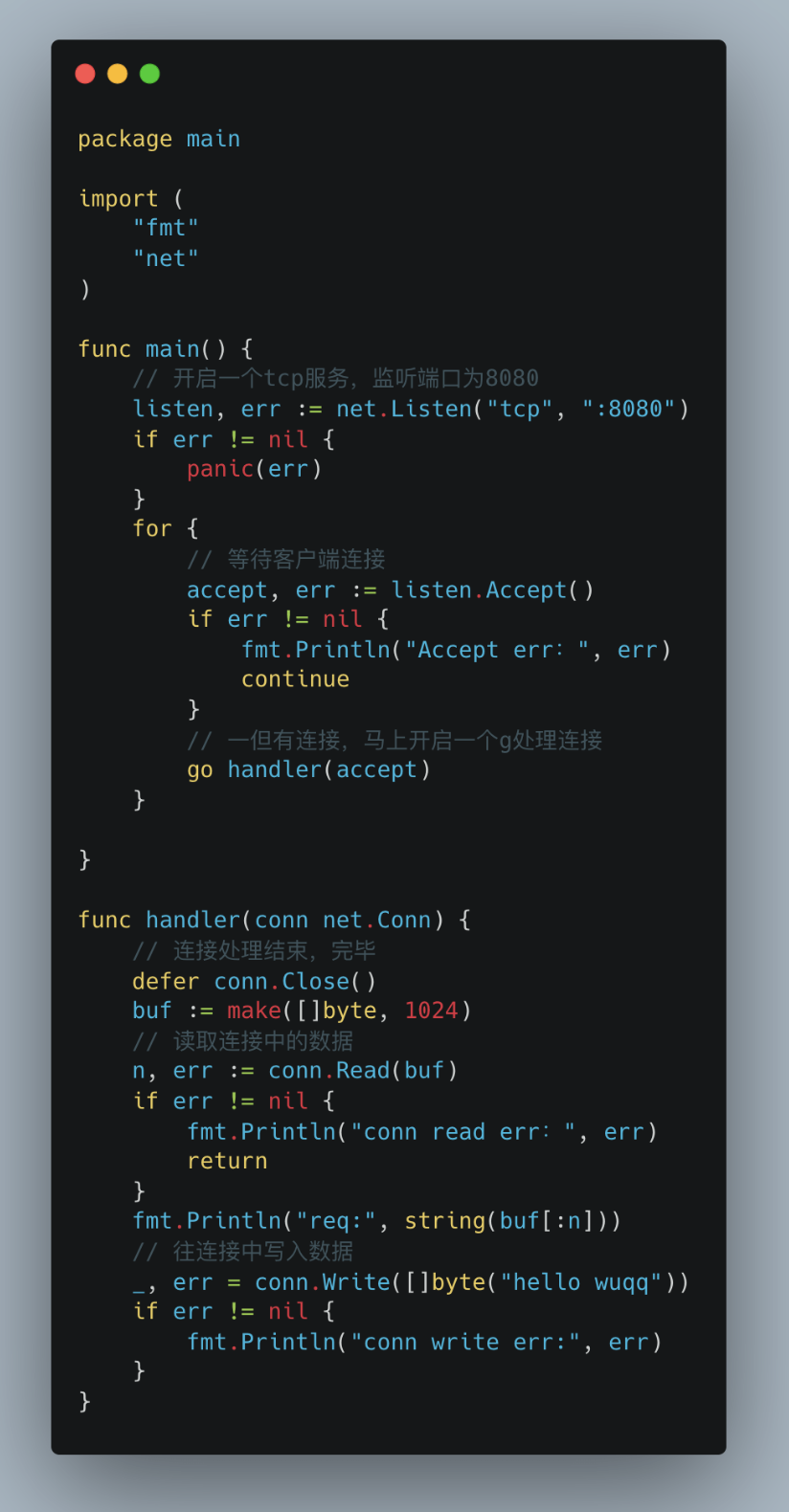
很简单一个demo,开启一个tcp服务。然后每来一个连接,就启动一个g去处理连接。处理完毕,关闭连接。
而且我们使用的是同步的模式去编写异步的逻辑,一个连接对应一个g处理,极其简单和易于理解。go标准库中的http.server也是这么干的。
针对上面的tcp服务demo,我们需要关注这段代码底层都发生了什么。
上面代码中主要涉及底层的一些结构。
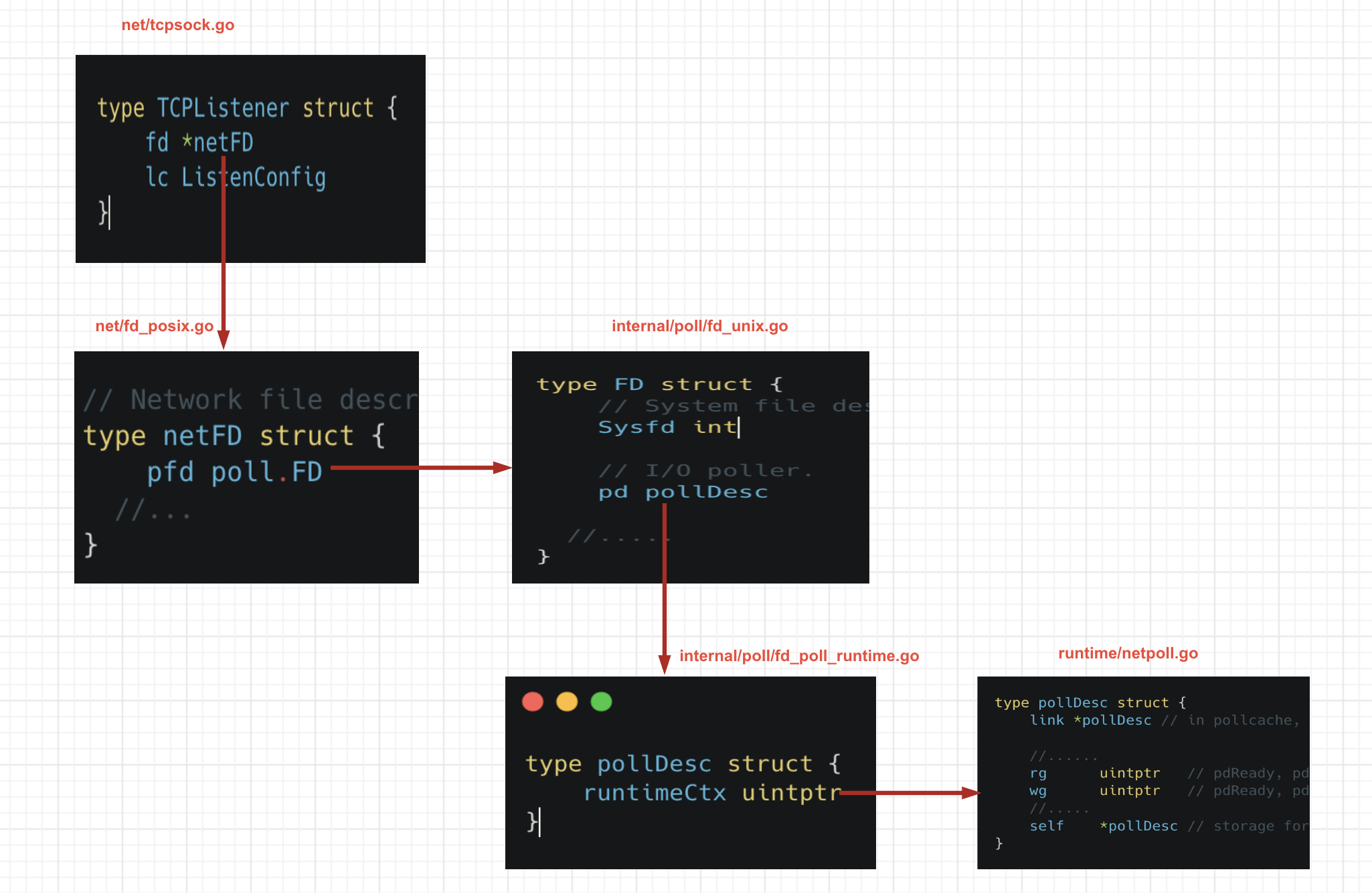
先简单解释一波。
- TCPListener:我们开启的是一个TCP服务,那当然就是TCP服务的网络监听器。
- netFD:网络描述符。Go中所有的网络操作都是以netFD实现的,它和底层FD做绑定。
- FD:文件描述符。net和os包把这个类型作为一个网络连接或者操作系统文件。其中里面一个字段Sysfd就是具体文件描述符值。
- pollDesc:I/O轮询器。说白了它就是底层事件驱动的封装。其中的runtimeCtx是一个指针类型,具体指向runtime/netpoll 中的pollDesc.
当然图上面结构字段都是阉割版的,但是不影响我们这篇文章。
还有一个问题,为什么结构上需要一层一层嵌入呢?
我的理解是每下一层都是更加抽象的一层。它是可以作为上一层具体的一种应用体现。
是不是跟没说一样?哈哈。
举例,比如这里的netFD表示网络描述符。
它的上一层可以是用于TCP的网络监听器TCPListener,那么对应的接口我们能想到的有两个Accept以及close。
对于Accept 动作,一定是返回一个连接类型 Conn ,针对这个连接,它本身也存在一个自己的netFD,那么可想而知一定会有 Write和Read两个操作。
而所有的网络操作都是以netFD实现的。这样,netFD在这里就有两种不用的上层应用体现了。
好了,我们需要搞清楚几件事:
- 一般我们用其他语言写一个tcp服务,必然会写这几步:socket->bind->listen,但是Go就一个Listen,那就意味着底层包装了这些操作。它是在哪一步完成的?
- Go是在什么时候初始化netpoll的,比如linux下初始化epoll实例。
- 当对应fd没有可读或者可写的IO事件而对应被挂起的g,是如何知道fd上的I/O事件已ready,又是如何唤醒对应的g的?
Listen解析
带着这些问题,我们接着看流程。

上图已经把当你调用Listen操作的完整流程全部罗列出来了。就像我上面列出的结构关系一样,从结构层次来说,每调用下一层,都是为了创建并获取下一层的依赖,因为内部的高度抽象与封装,才使得使用者往往只需调用极少数简单的API接口。
现在我们已经知道事例代码涉及到的结构以及对应流程了。
在传统印象中,创建一个网络服务。需要经过:创建一个socket、bind 、listen这基本的三大步。
前面我们说过,Go中所有的网络操作都是以netFD实现的。go也是在这一层封装这三大步的。所以我们直接从netFD逻辑开始说。
上图是在调用socket函数这一步返回的netFD,可想而之核心逻辑都在这里面。
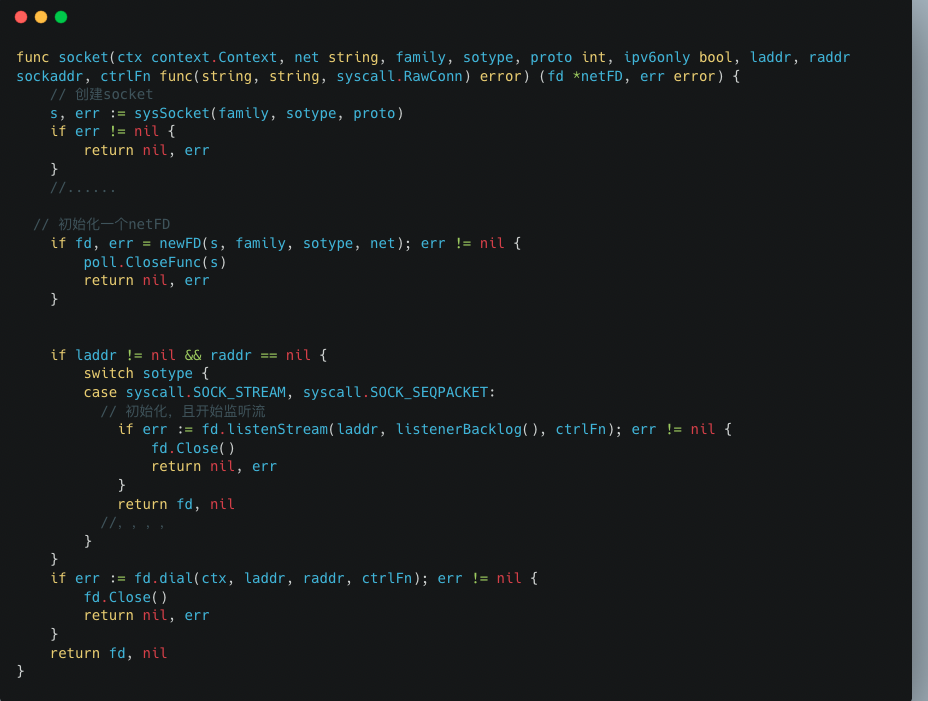
我们可以把这个函数核心点看成三步。
- 调用sysSocket函数创建一个socket,返回一个文件描述符(file descriptor),简称fd下文。
- 通过sysSocket返回的fd,调用newFD函数创建一个新的netFD。
- 调用netFD自身的方法listenStream函数,做初始化动作,具体详情下面再说。
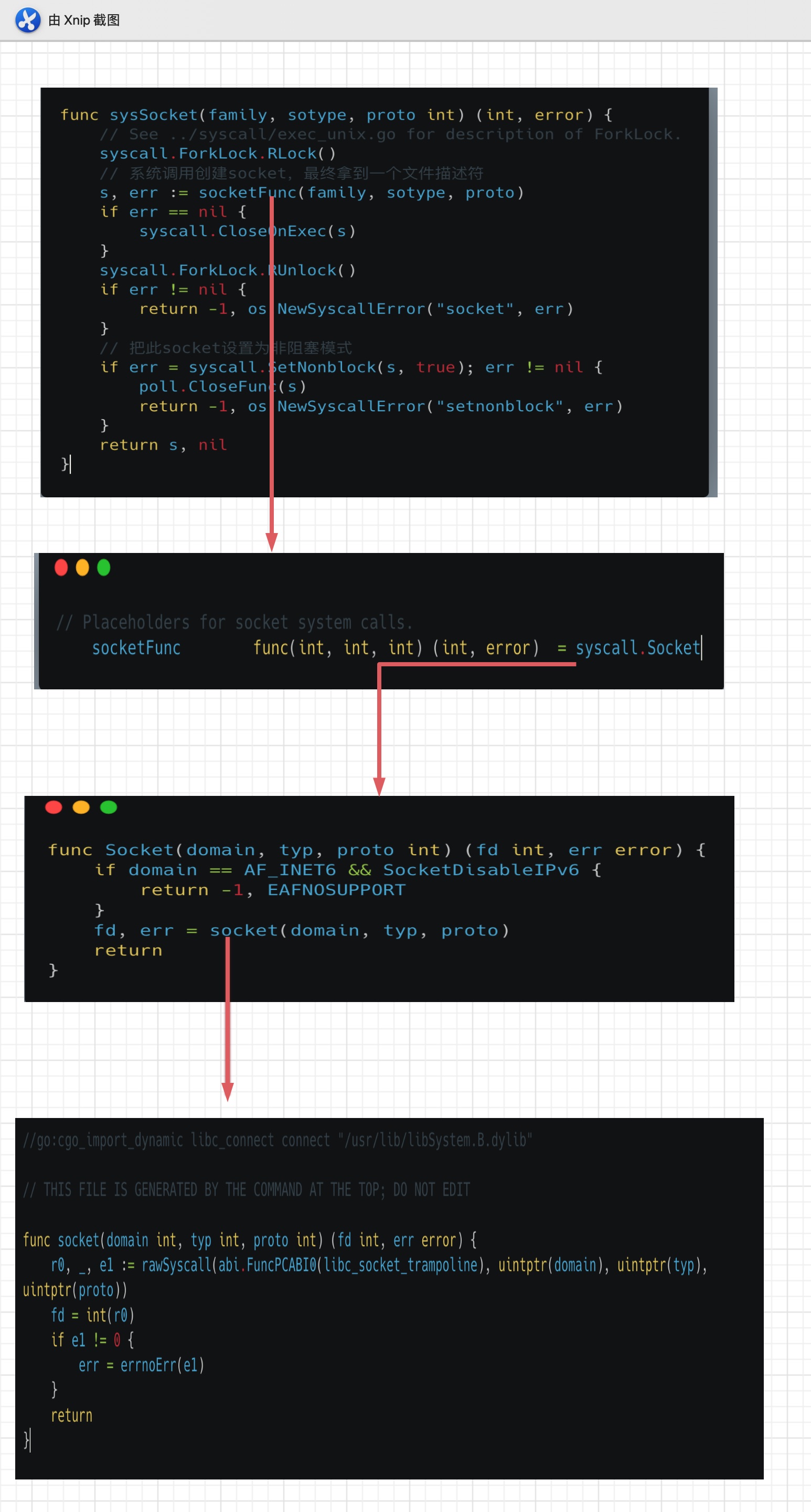
在sysSocket函数中,首先会通过socketFunc来创建一个socket,通过层层查看,最终是通过system call来完成这一步。当获取到对应fd时,会通过syscall.SetNonblock函数把当前这个fd设置成非阻塞模式,这样当这个Listener调用accept函数就不会被阻塞了。
第二步,通过第一步创建socket拿到的fd,创建一个新的netFD。这段代码没啥好解释的。
第三步,也就是最核心的一步,调用netFD自身的listenStream方法。
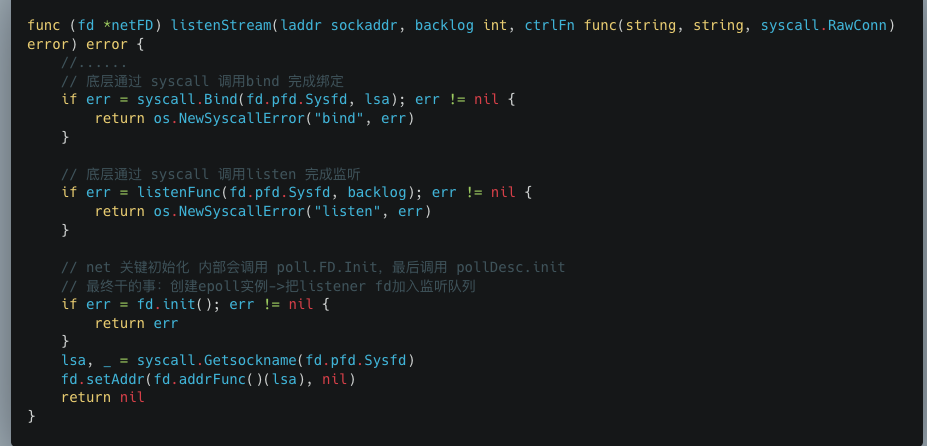
listenStream里面也有核心的三步:
- 通过syscall.Bind 完成绑定
- 通过listenFunc 完成监听
- 调用netFD自身init完成初始化操作:netFD.init ->poll.FD.init->FD.pollDesc.init
我们主要看fd.init逻辑。
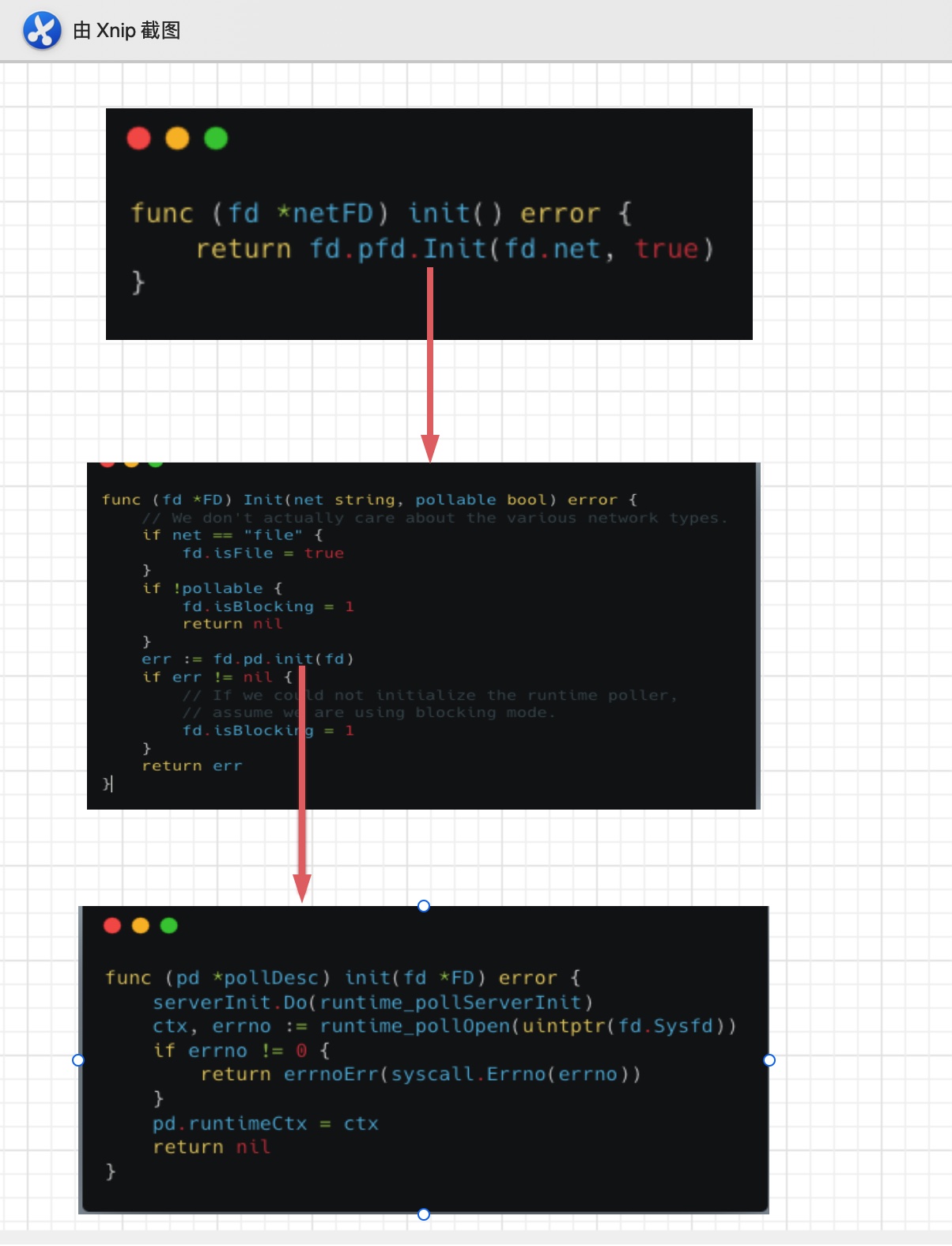
最终是调用的pollDesc的init函数。这个函数有重要的两步。
- runtime_pollServerInit:主要会根据不同的平台去调用对应平台的netpollInit函数来创建I/O多路复用的实例。比如linux下创建epoll。
- runtime_pollOpen(uintptr(fd.Sysfd)):主要将已经创建完的Listener fd注册到上述实例当中,比如将fd注册到epoll中,底层通过syscall调用epoll_ctl。
更具体的流程,
首先serviceInit.Do 保证当中的runtime_pollServerInit只会初始化一次。这很好理解,类似epoll实例全局初始化一次即可。
接着我们看下runtime_pollServerInit函数,

这是咋回事,和我们平常看过的函数长的不太一样,执行体呢?
其实这个函数是通过 go:linkname连接到具体实现的函数poll_runtime_pollServerInit。找起来也很简单,
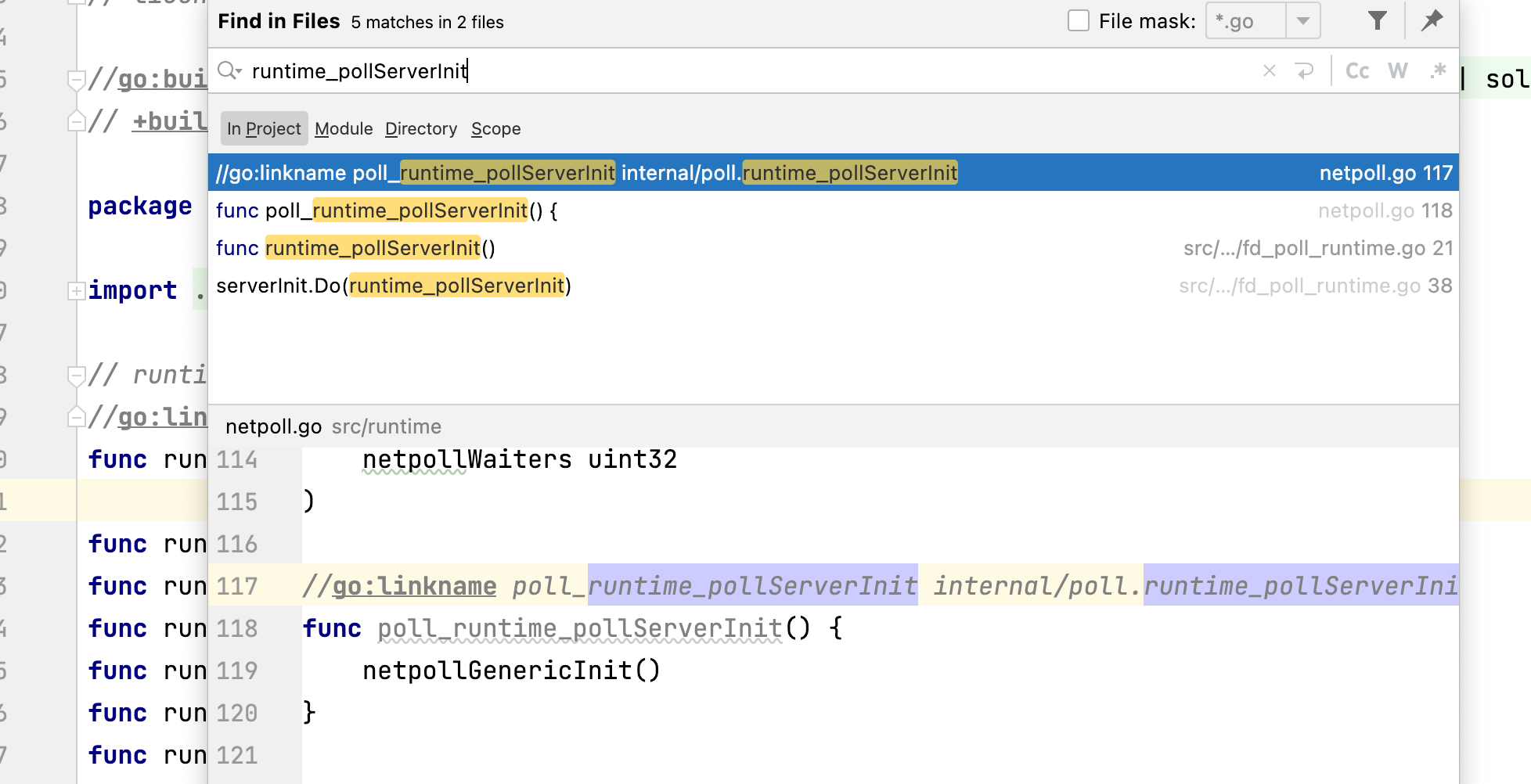
看到poll_runtime_pollServerInit()上面的 //go:linkname xxx 了吗?不了解的可以看看Go官方文档`go:linkname。
所以最终runtime_pollServerInit调用的是,
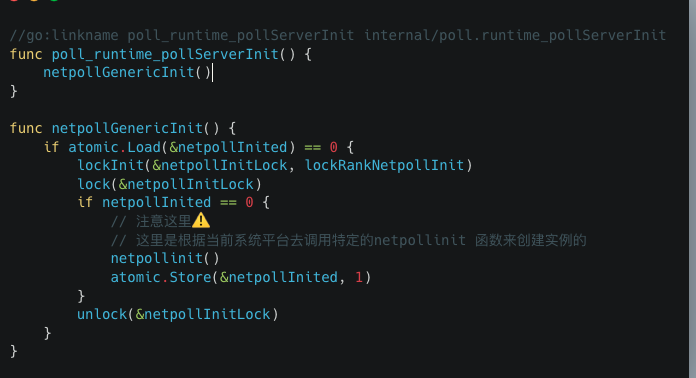
通过调用poll_runtime_pollServerInit->netpollGenericInit,netpollGenericInit里调用netpollinit函数完成初始化。
注意。这里的netpollinit,是基于当前系统来调用对应系统的netpollinit函数的。
什么意思?
文章开始有提到Go底层网络模型是基于I/O多路复用。
不同平台对I/O多路复用有不同的实现方式。比如Linux的epoll,MacOS的kqueue,而Windows的icop。
所以对应,如果你当前是Linux,那么最终调用的是src/runtime/netpoll_epoll.go下的 netpollinit函数,然后会创建一个epoll实例,并把值赋给epfd,作为整个runtime中唯一的event-loop使用。
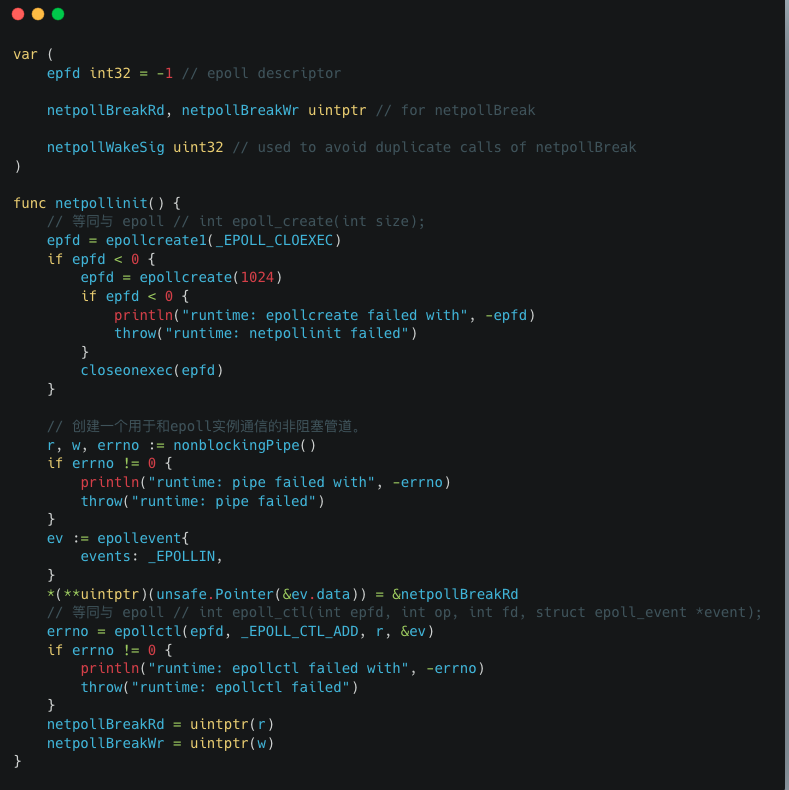
其他的,比如MacOS下的kqueue,也存在netpollinit函数。
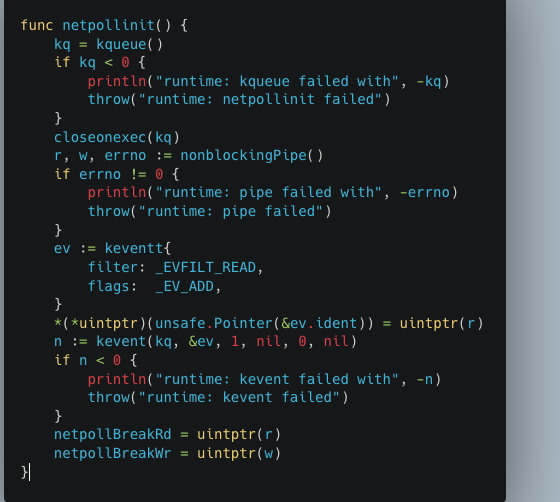
以及Windows下的icop。
我们回到pollDesc.init 操作,
完成第一步初始化操作后,第二步就是调用runtime_pollOpen。
老套路通过**//go:linkname**找到对应的实现,实际上是调用的poll_runtime_pollOpen函数,这个函数里面再调用netpollopen函数,netpollopen函数和上面的netpollinit函数一样,不同平台都有它的实现。linux平台下,
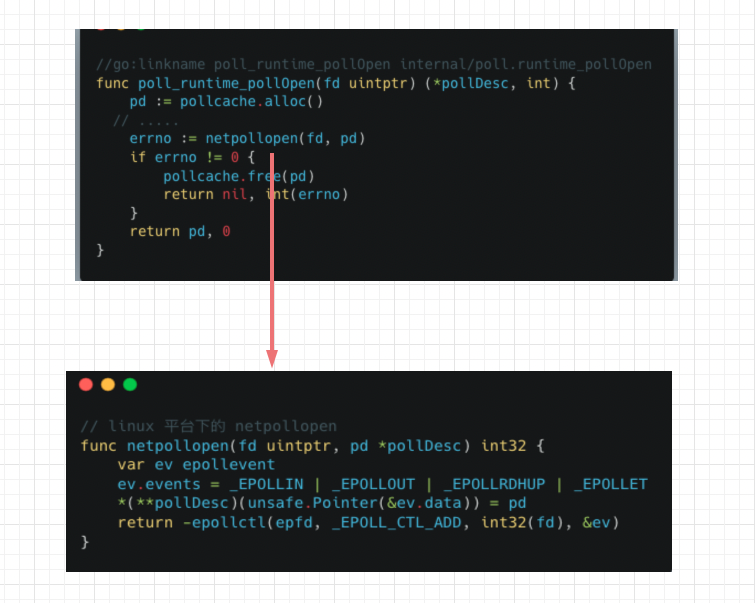
netpollopen函数,首先会通过指针把pollDesc保存到epollevent的一个字节数组data里。
然后会把传递进来的fd(刚才初始化完成的那个Listener监听器)注册到epoll当中,且通过指定 _EPOLLET将epoll设置为边缘触发(Edge Triggered)模式。如果让我用一句话来说明epoll水平触发和边缘触发的区别,那就是,
水平触发下epoll_wait在文件描述符没有读写完会一直触发,而边缘触发只在是在变成可读写时触发一次。
到这里整个Listen 动作也就结束了,然后层层返回。最终到业务返回的是一个 Listener,按照本篇的例子,本质上还是一个TCPListener。
Accept解析
接着当我们调用listen.Accept的时候,
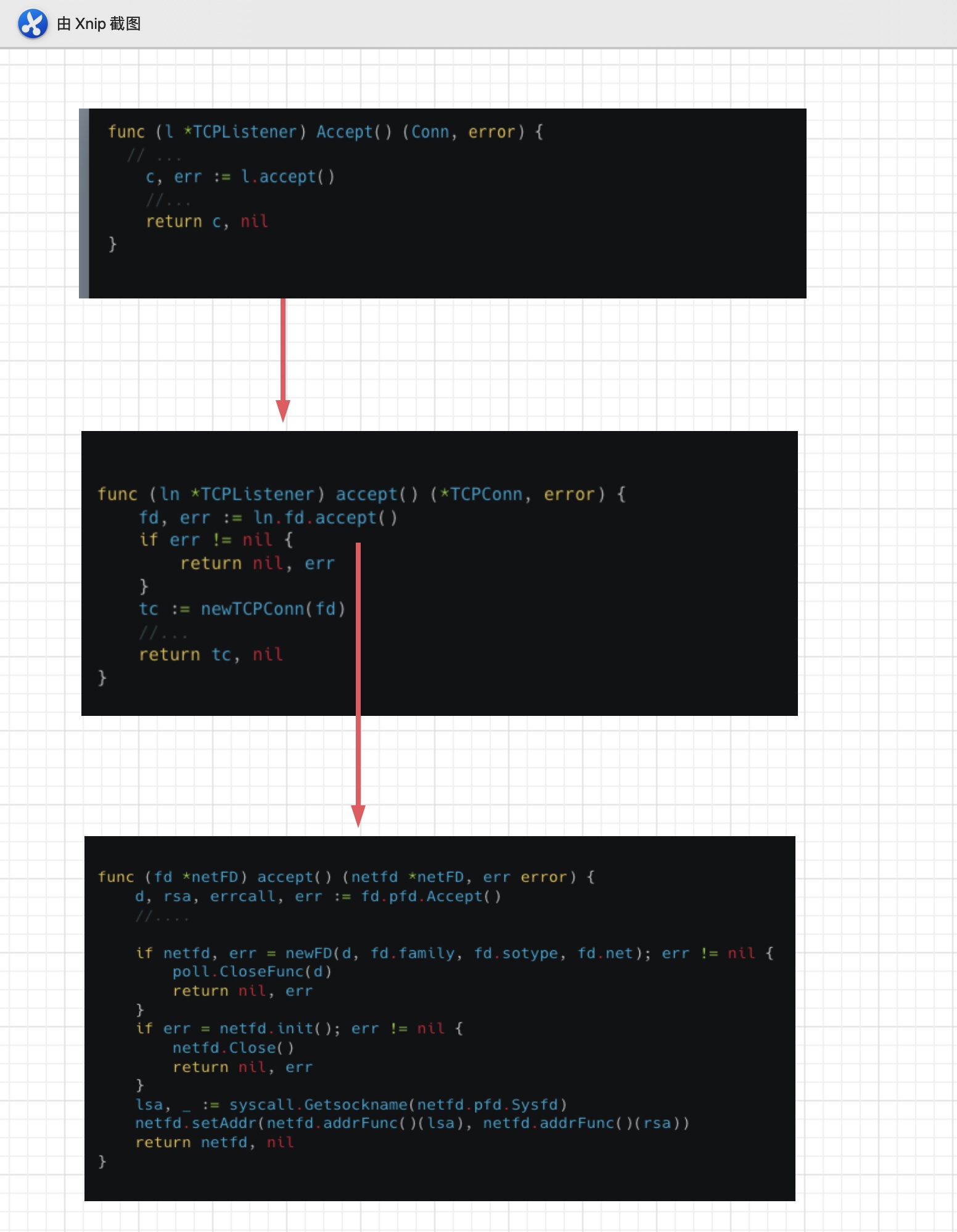
最终netFD的accept函数。netFD中通过调用fd.pfd(实际上是FD)的Accept函数获取到socket fd。通过这个fd创建新的netFD表示这是一个新连接的fd。并且会和Listen时一样调用netFD.init做初始化,因为当前epoll已经初始化一次了,所以这次只是把这个新连接的fd也加入到epoll事件队列当中,用于监听conn fd的读写I/O事件。
具体我们看FD.Accept是咋么执行的。
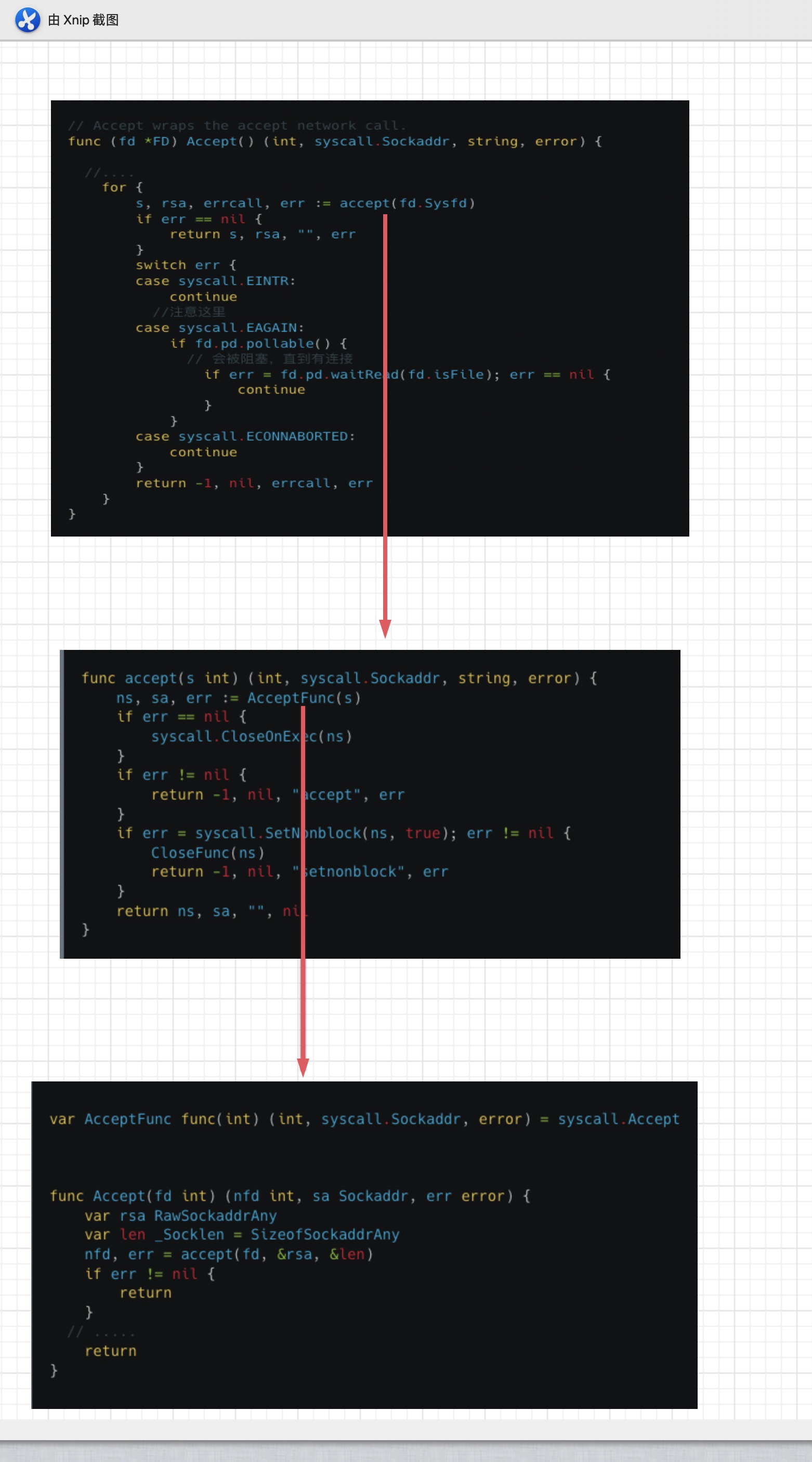
首先是一个死循环for,死循环里调用了accept函数,本质上通过systcall调用系统accept接收新连接。当有新连接时,最终返回一个文件描述符fd。当accept获取到一个fd,会调用systcall.SetNonblock把这个fd设置成非阻塞的I/O。然后返回这个连接fd。
因为我们在Listen的时候已经把对应的Listener fd设置成非阻塞I/O了。所以调用accept这一步是不会阻塞的。只是下面会进行判断,根据判断 err ==syscall.EAGAIN 来调用fd.pd.waitRead阻塞住用户程序。
直到I/O事件ready,被阻塞在fd.pd.waitRead的代码会继续执行continue,重新一轮的accept, 此时对应fd上的 I/O已然ready,最终就返回一个conn类型的fd。
我刚才说的调用fd.pd.waitRead会被阻塞,直到对应I/O事件ready。我们来看它具体逻辑,
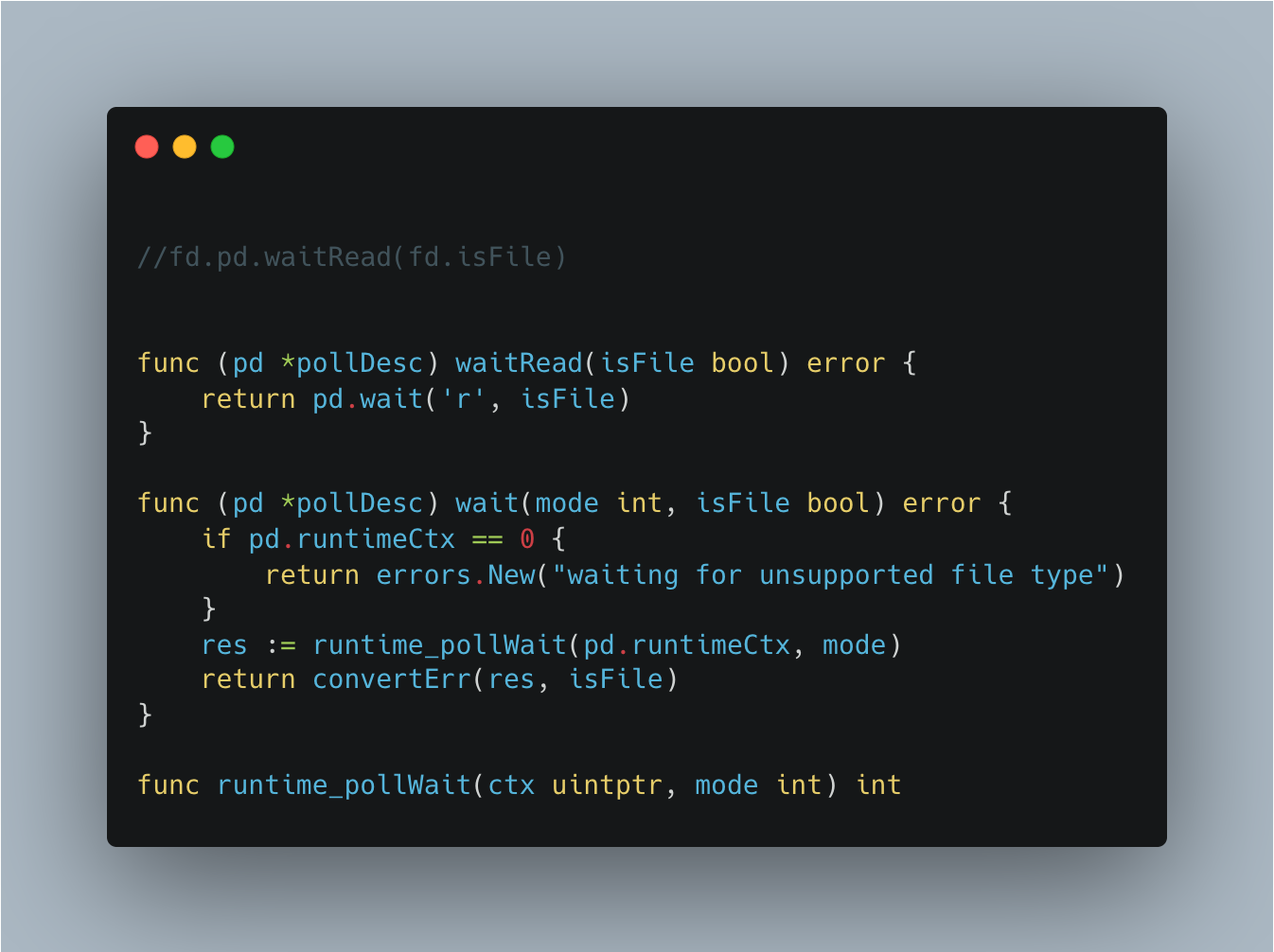
最终到runtime_pollWait函数,老套路了,我们找到具体的实现函数。
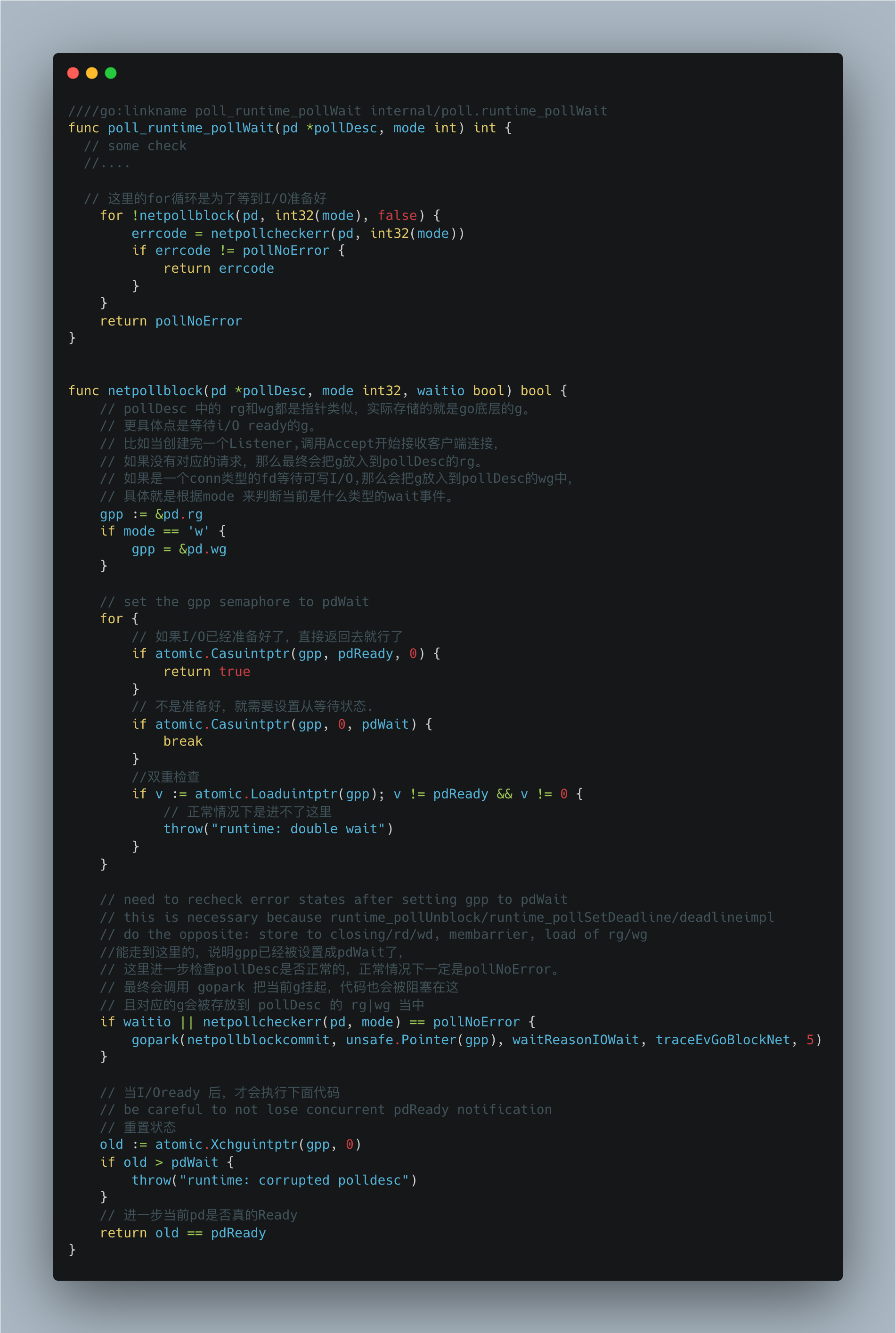
poll_runtime_pollWait 里的for循环就是为了等待对应的I/O ready才会返回,否则的话一直调用netpollblock函数。pollDesc结构我们之前提到,它就是底层事件驱动的封装。其中有两个重要字段: rg和wg,都是指针类型,实际这两个字段存储的就是Go底层的g,更具体点是等待i/O ready的g。
比如当创建完一个Listener,调用Accept开始接收客户端连接。如果没有对应的请求,那么最终会把g放入到pollDesc的rg。
如果是一个conn类型的fd等待可写I/O,那么会把g放入到pollDesc的wg中。
具体就是根据mode来判断当前是什么类型的等待事件。
netpollblock里也有一个for循环,如果已经ready了,那么直接返回给上一层就行了。否则的话,设置gpp为等待状态pdWait。
这里还有一点atomic.Loaduintptr(gpp),这是为了防止异常情况下出现死循环问题。比如如果gpp的值不是pdReady也不是0,那么意味着值是pdWait,那就成了double wait,必然导致死循环。
如果gpp未ready且成功设置成pdWait,正常情况下,最终会调用gopark,会挂起g且把对应的g放入到pollDesc 的wg|rg 当中。
进入gopark。
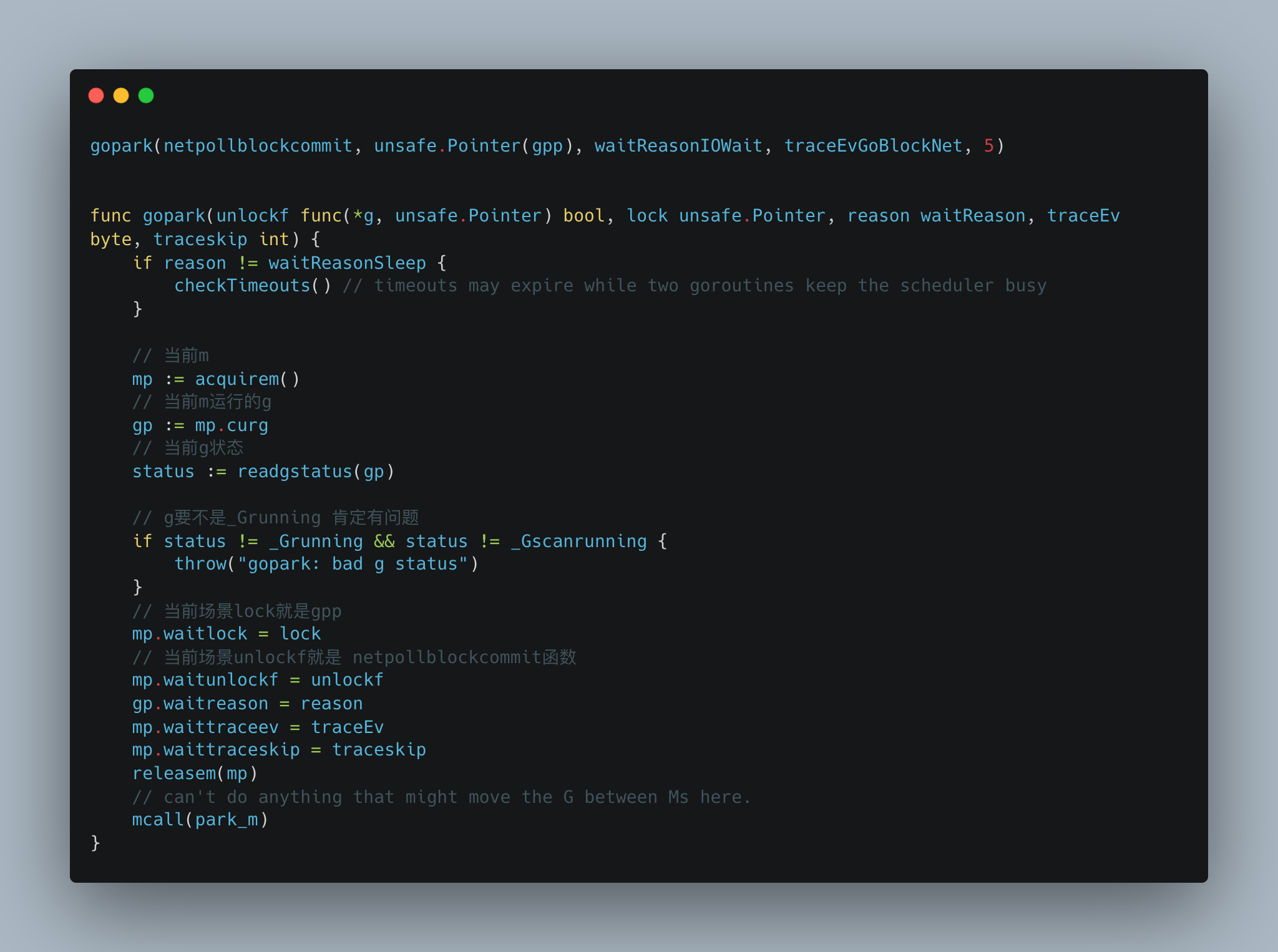
这一块代码不是很难懂,基本的字段打了备注,核心还是要看park_m这个函数。
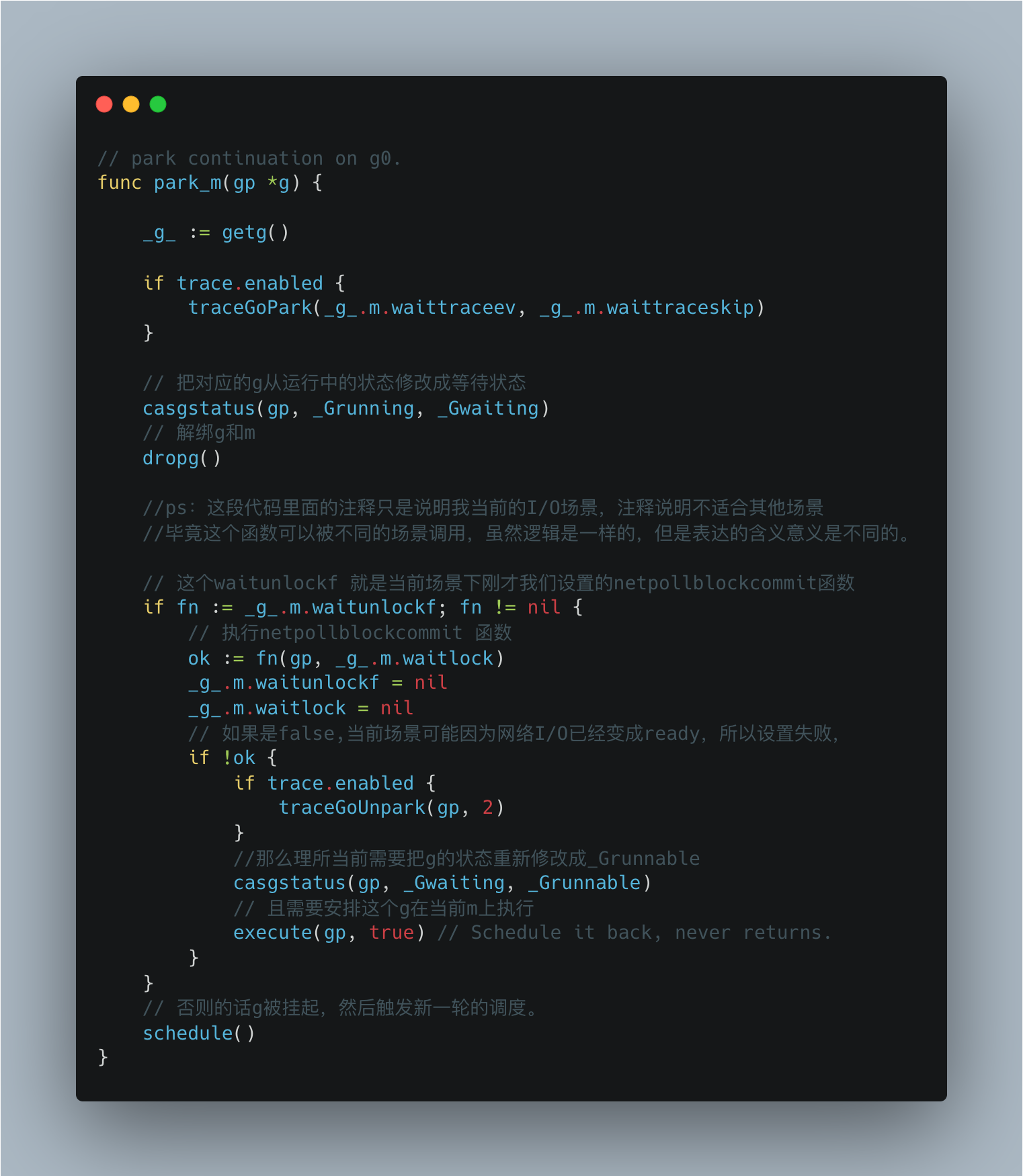
park_m函数中,首先会通过CAS并发安全的修改g的状态。然后调用dropg解绑g和m的关系,也就是m把当前运行的g置空,g把当前绑定的m置空。
后面的代码是根据当前场景来解释的。我们知道此时m的waitunlockf 其实就是netpollblockcommit。
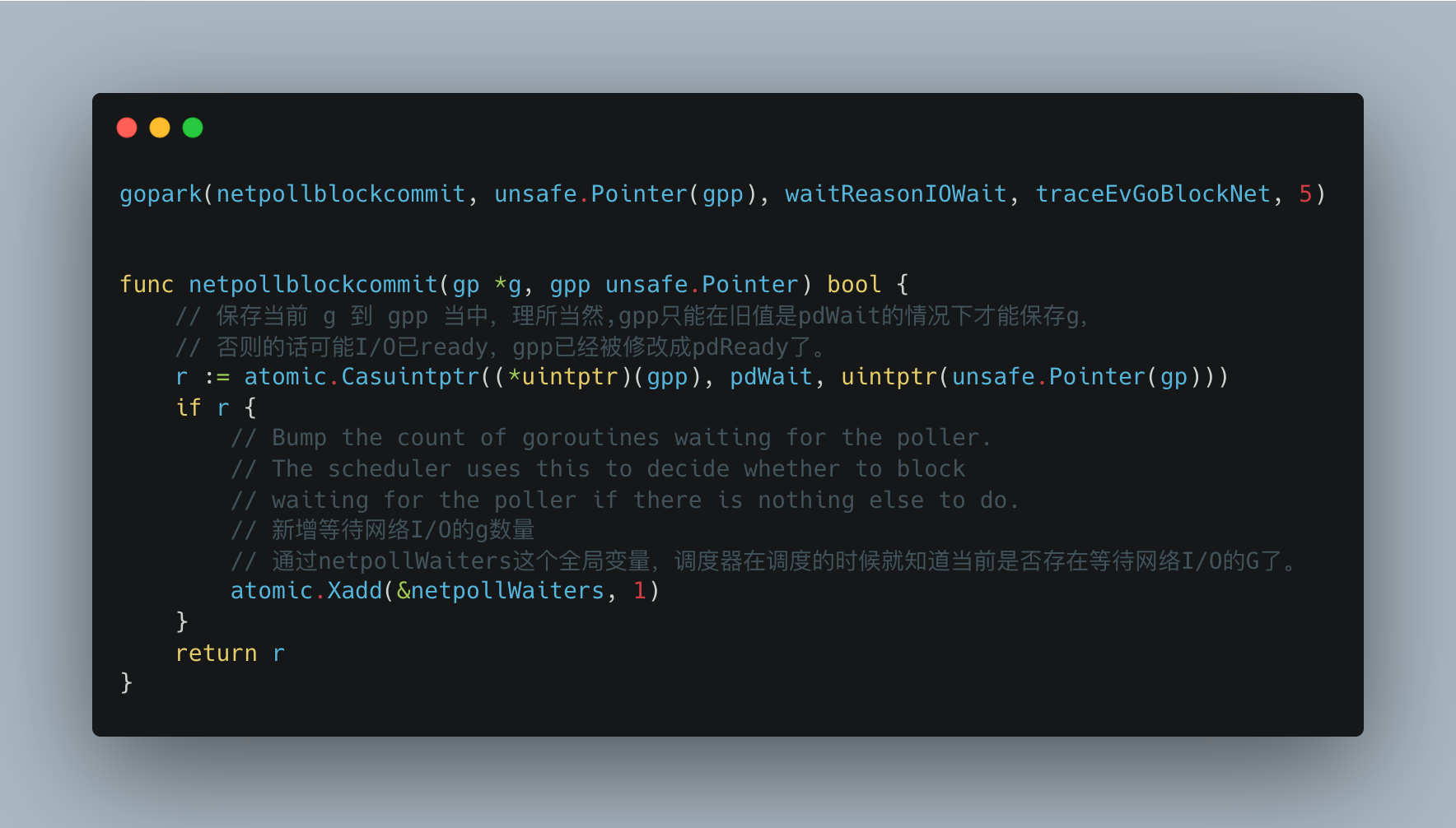
netpollblockcommit会把当前已经是_Gwaiting状态下的g赋值给gpp。如果赋值成功,netpollWaiters会加1。这个全局变量表示当前等待I/O事件ready的g数量,调度器再进行调度的时候可以根据此变量判断是否存在等待I/O事件的g。
如果此时当前gpp下的fd的I/O已经ready。那么gpp的状态必然已不是pdWait,赋值失败。返回false。
回到park_m,
如果netpollblockcommit返回true,那么直接触发新一轮的调度。
如果netpollblockcommit返回false,意味着当前g已经不需要被挂起了,所以需要把状态调整为_Grunnable,然后安排g还是在当前m上执行。
当I/O事件ready,会一层层返回,获取到新的socket fd,创建conn类型的netFD,初始化netFD(其实就是把这个conn类型的fd也加入epoll事件队列,用于监听),最终最上游会获取到一个Conn类型的网络连接,就可以基于这个连接做Read、Write等操作了。
Read/Write 解析
后续的Conn.Read 和 Conn.Write 原理和Accept 类似。
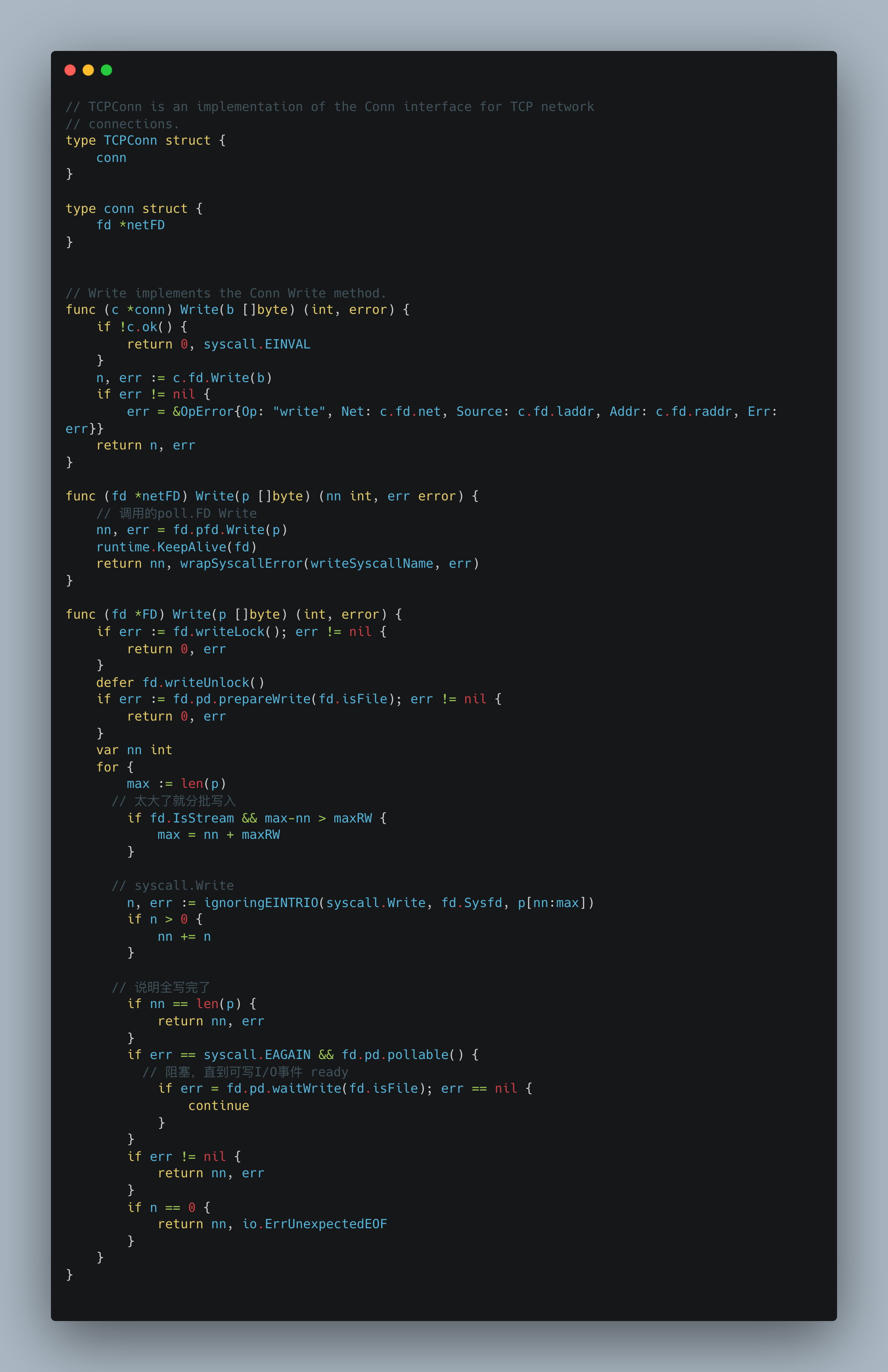
给出了Write操作,可以看出核心部分和accept操作时一样的。对于Read操作,就不再重复了。
从上面的分析中我们已经知道,Go的netpoller底层通过对epoll|kqueue|iocp的封装,使用同步的编程手法达到异步执行的效果,无论是一个Listener还是一个Conn,它的核心都是netFD,netFD又和底层的PollDesc结构绑定,当读写出现EAGAIN错误时,会通过调用gopark把当前g给park住,同时会将当前的g存储到对应netFD的PollDesc的wg|rg当中, 直到这个netFD再次发生对应的读写事件,才会重新把当前g放入到调度系统进行调度。
还有最后一个问题,我们咋么知道哪些FD发生读写事件了?
I/O已就绪
答案就是netpoll()函数。
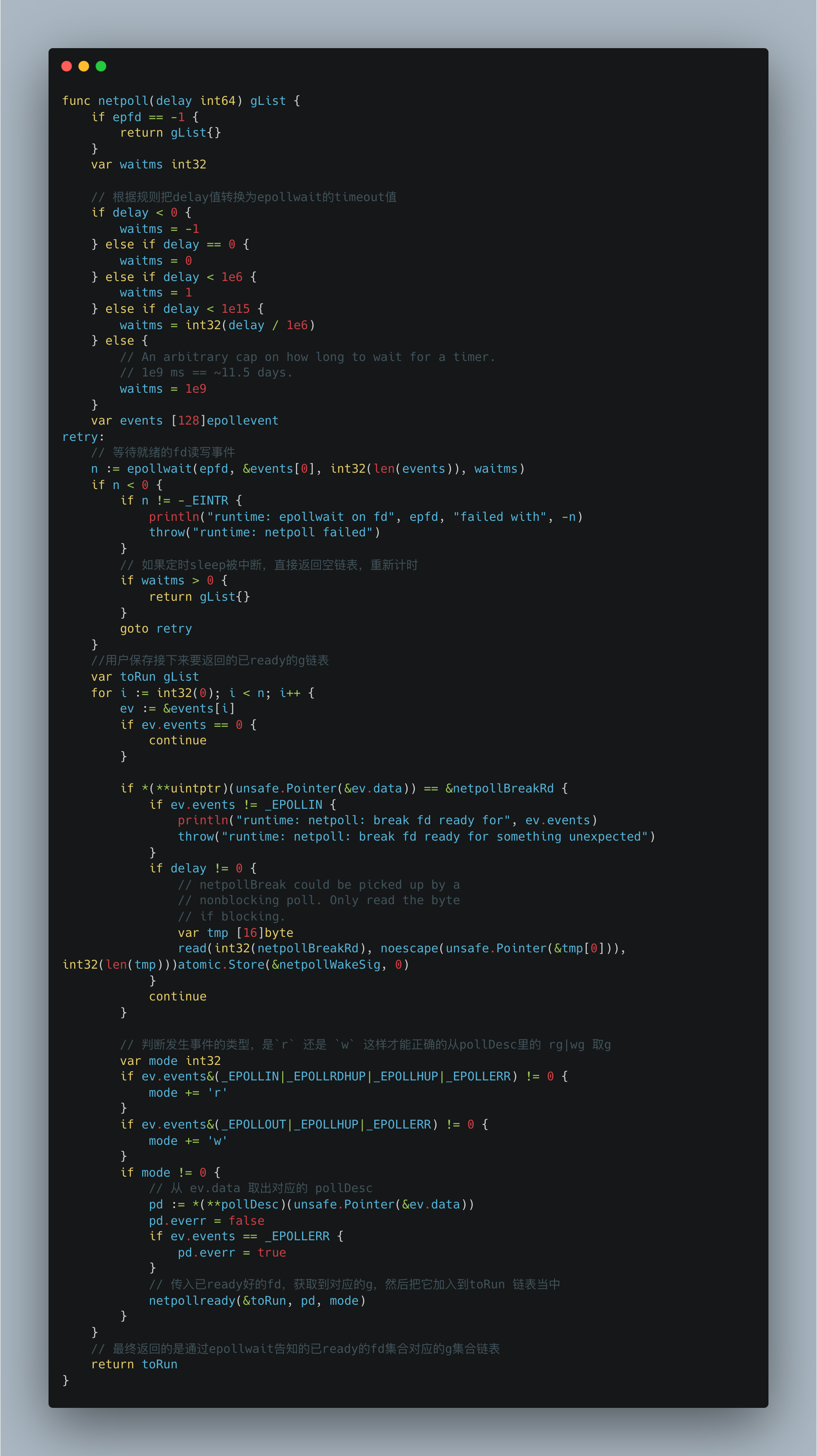
此函数会调用epollwait函数,本质上就是Linux中epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout)。
在之前调用epoll_ctl,注册fd对应的I/O事件到epoll实例当中。这里的epoll_wait实际上会阻塞监听epoll实例上所有fd的I/O事件,通过传入的第二个参数(用户内存地址events)。
当有对应的I/O事件到来时,内核就会把发生事件对应的fd复制到这块用户内存地址(events)。解除阻塞,然后我们遍历这个events,去获取到对应的事件类型、pollDesc,再通过调用netpollready函数获取到pollDesc对应被gopark的g,最终把这些g加入到一个链表当中,返回。
也就是说只要调用这个函数,我们就能获取到之前因为I/O未ready而被gopark挂起,现在I/O已ready的g链表了。
我们可以找到四个调用处,如下,
- startTheWorldWithSema
- findrunnable
- pollWork
- sysmon
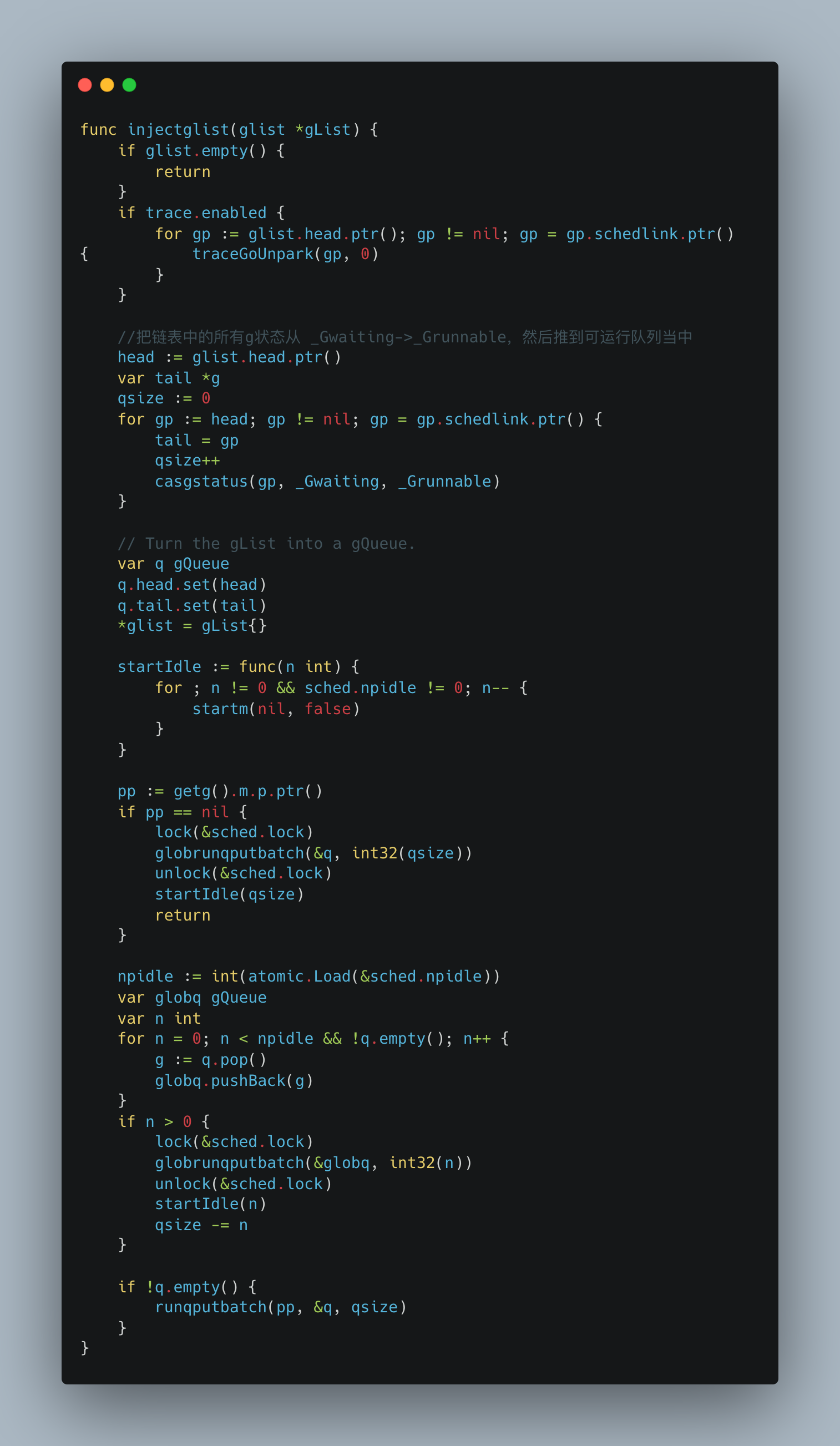
这和go的调度有关,当然这不是本章的内容。当这四种方法调用netpoll函数得到一个可运行的g链表时,都会调用同一个函数injectglist。这个函数本质上就是把链表中所有g的状态从_Gwaiting->_Grunnable。然后按照策略,把这些g推送到本地处理器p或者全家运行队列中等待被调度器执行。
到这里,整个流程就已经剖析完毕。不能再写了。
最后
Go netpoller通过在底层对epoll/kqueue/iocp这些不同平台下对I/O多路复用实现的封装,加上自带的goroutine(上文我一直用g表达),从而实现了使用同步编程模式达到异步执行的效果。 代码很长,涉及到的模块也很多,整体看完代码还是非常爽的。
另外早有人提出,由于一个连接对应一个goroutine,瞬时并发场景下,大量的goroutine会被不断创建。且原生netpoller无法提供足够的性能和控制力,如无法感知连接状态、连接数量多导致利用率低、无法控制协程数量等。针对这些问题,可以参考下gnet以及 KiteX 这两个项目的网络模型。
参考资料
